
Ever have J streams of data that, maybe don't fit so well in memory. Well you can lazy load them! But... what if you want to do lookups/labelling tasks with some primary Key in another dataframe(i rows long)? Do you really want to run the cost of iterating i times to do J joins? Probably not - well maybe, but - probably not.
That's where LockandKeyLookups comes into play. LockandKeyLookups are iterators that can be instantiated like the following:
lakl = LockandKeyLookup( key, tumbler,
key_lookup_fn, pin_lookup_fn,
emitter_fn = ( k, t ) -> k == t)Where the tumbler is some array of iterables like DataFrames, key is some iterable, and the arguments labelled _fn are functions that do the following:
key_lookup_fn&pin_lookup_fn: are the functions used to index the key and tumbler pins for a match condition.emitter_fn: is the function used to assess whether the result of the lookup_fn's between a key and a given pin is satisfied.
so we can iterate these instances in for loops, or collections as usual.
[ iter for iter in lakl ]where the structure of the iter item is the following ( Key_Index[i] => ( Tumbler_Index[J], Pin_Index[Q] ) ) = iter
So this gives us a mapping between a single key, and a single pin at a time.
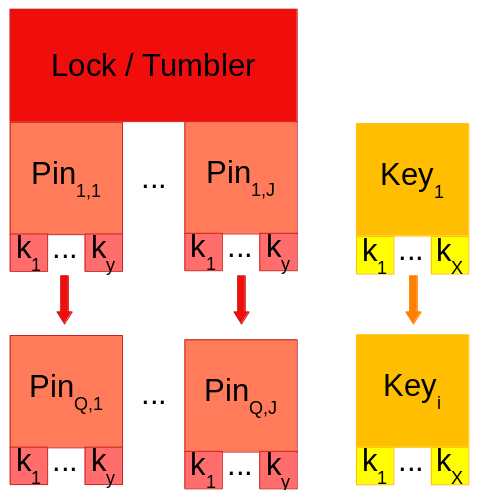
- The items must be sorted by the associated key for this to work!
- Only tested with DataFrames
each(row)iterables so far. - Might not be the fastest option. But it's not very steppy, and should work with lazy iterators.